Table of Contents
- Introduction
- Background on LSMs
- The Rise of NVMe SSDs
- Revisiting Traditional Database Designs: B+ Trees and Update-in-Place Models
- Introducing TreeLine: A New Paradigm
- Innovative Techniques in TreeLine
- Conclusion
- Refereces

Introduction
In the digital era, the performance of database systems is pivotal, underpinning technology-driven solutions across various industries. Traditionally, systems like RocksDB and LevelDB have relied on log-structured merge-tree (LSM) technologies, optimized for earlier storage environments where write performance was crucial. However, with the advent of Non-Volatile Memory Express (NVMe) SSDs, the storage landscape has radically transformed. NVMe SSDs drastically improve latency, throughput, and parallel I/O capabilities—key features for today's data-intensive applications.
This significant advancement challenges traditional database architectures, including LSM's sequential write optimization, and paves the way for innovative designs like TreeLine DB. TreeLine leverages NVMe's strengths to enhance both read and write efficiencies, thereby reshaping database performance expectations. As NVMe technology continues to evolve, it is essential to align database design with these hardware advancements to fully exploit their potential and drive superior performance.
Background on LSMs
Log-Structured Merge-trees (LSMs) are sophisticated data structures that have been designed with a primary focus on optimizing write performance, especially in environments where random writes incur significant overhead. This scenario is typical with traditional hard disk drives (HDDs) and earlier generations of solid-state drives (SSDs). LSMs effectively address this challenge by adopting a strategy where data is initially written in a sequential manner into a memory-resident structure known as a 'memtable'. Once the memtable reaches its capacity, it is flushed to disk as an immutable 'SSTable' (Sorted String Table).
The true prowess of LSMs lies in their approach to managing these SSTables. As more data is written and more SSTables are created, LSMs periodically merge these tables in the background. This merging process, while beneficial for managing space and ensuring that newer writes are integrated with older data, does introduce significant overhead, particularly impacting read operations.
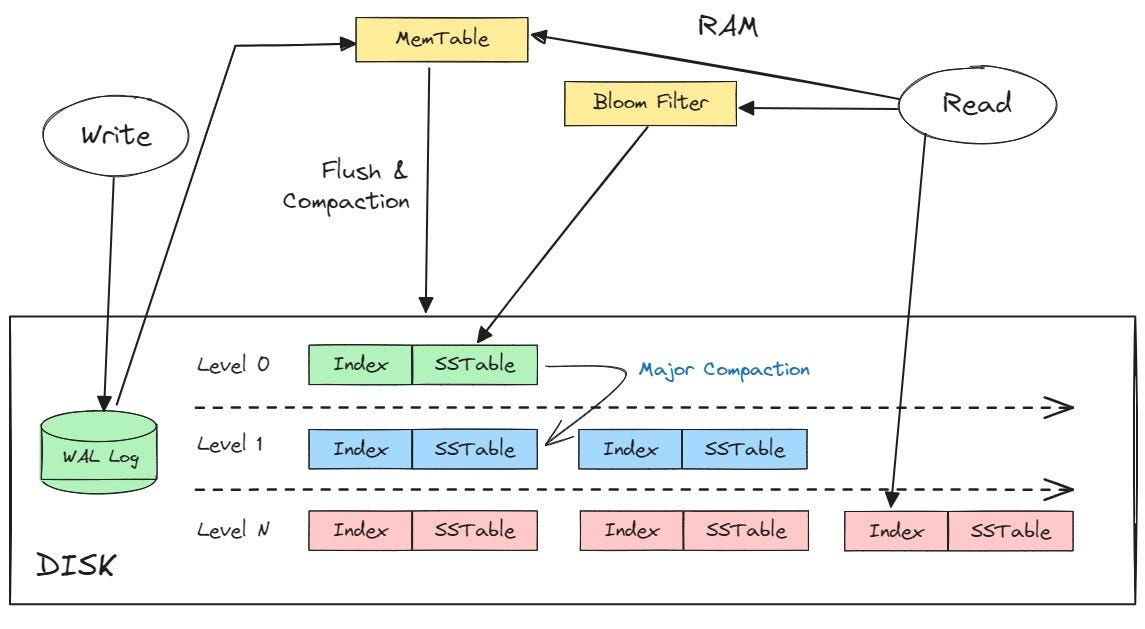
To mitigate the impact on read performance, LSMs employ several mechanisms:
Bloom filters:These are probabilistic data structures used to test whether an element is a member of a set. In the context of LSMs, Bloom filters are crucial for quickly determining whether a sought key might be in an SSTable without actually reading the SSTable, thereby reducing unnecessary disk reads.Compaction processes:These are operations that merge multiple SSTables into fewer SSTables. Compaction helps in reducing the number of SSTables that need to be checked during a read operation and also in reclaiming space used by deleted or overwritten items.
While these mechanisms do help in maintaining an efficient system, they come with their own set of complexities and can lead to increased latency in read operations. Additionally, the continuous process of merging and compacting can lead to what is known as 'write amplification', where more data is written to the storage medium than was originally intended. This not only affects the overall performance but can also reduce the lifespan of SSDs by increasing the wear and tear on the devices.
As we explore the advancements in storage technology, particularly the rise of NVMe SSDs, it's essential to evaluate whether the traditional advantages of LSMs still hold true or if newer data structures might offer more optimal solutions in light of contemporary hardware capabilities.
The Rise of NVMe SSDs
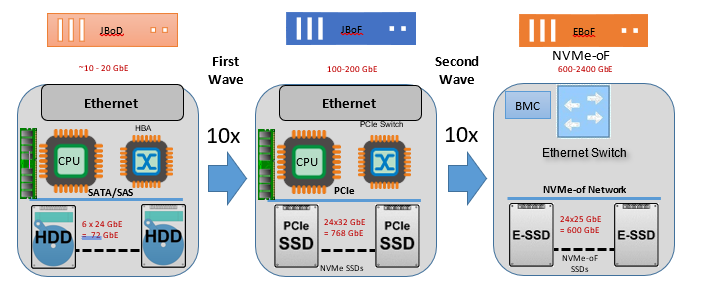
The advent of Non-Volatile Memory Express (NVMe) solid-state drives (SSDs) has significantly transformed the storage landscape. NVMe SSDs leverage the parallelism of modern CPUs and interfaces to deliver dramatic improvements over traditional hard disk drives (HDDs) and older SSDs. By connecting directly through the PCIe interface, NVMe SSDs drastically reduce data access latency from milliseconds to microseconds and offer a substantial increase in throughput—reaching speeds several times that of SATA SSDs.
NVMe technology excels in handling multiple input/output operations simultaneously through thousands of parallel queues, greatly benefiting applications requiring high random access. This capability enables NVMe SSDs to efficiently manage both random and sequential write operations, challenging the necessity of log-structured merge-tree (LSM) storage engines designed for older technologies. As NVMe continues to advance, it reshapes storage performance fundamentals and opens new avenues in database management and application development.
Revisiting Traditional Database Designs: B+ Trees and Update-in-Place Models
In the realm of database architectures, the B+ tree stands as a classic design element, widely adopted due to its robust indexing structure and efficient query performance. Central to the B+ tree architecture is its update-in-place model, where changes to data are made directly in the location where the data originally resides. This model contrasts sharply with systems that write new data to different locations and subsequently update pointers.
------------------------------------
| 7 | 16 | | |
------------------------------------
/ | \
----------------- ---------------- -----------------
| 1 | 2 | 5 | 6 | | 9 | 12 | | | | 19 | 25 | | |
----------------- ---------------- -----------------
The B+ tree is primarily a leaf-oriented structure, with all data pointers and values stored at the leaf nodes, while the interior nodes maintain keys that serve as guides to these leaves. This structure facilitates rapid data retrieval and efficient range queries, making it particularly advantageous for read-heavy workloads. For instance, databases underpinning financial systems or analytics platforms, where query speed and data integrity are paramount, often leverage B+ trees to optimize read operations across vast datasets.
Moreover, the B+ tree architecture excels in environments with uneven write distributions. It maintains balanced trees through splits and merges, ensuring that the depth of the tree remains manageable and search operations stay efficient, even as datasets grow or become unevenly distributed. This adaptability is crucial for maintaining performance standards in dynamic real-world applications.
However, despite these strengths, B+ trees face significant challenges, particularly in modern database environments characterized by large-scale and high-throughput requirements. One major drawback is write amplification, where multiple writes are triggered by a single data update. This occurs because updates may necessitate rewriting entire nodes and subsequently propagating changes up the tree. In scenarios involving frequent updates or large-scale insert operations, this can lead to substantial overheads and degrade overall performance.
Additionally, B+ trees can exhibit inefficiencies in handling large-scale scans or bulk operations. Although efficient for individual queries, the sequential nature of leaf nodes means that operations affecting large portions of the database can become time-consuming as each node is processed in turn.
In light of these challenges, while B+ trees offer substantial benefits for certain types of workloads, their limitations underpin the ongoing evolution of database technologies. As storage technologies advance, particularly with the rise of NVMe SSDs, it becomes imperative to revisit and rethink traditional designs like B+ trees to better harness the capabilities of modern hardware.
Introducing TreeLine: A New Paradigm
In the rapidly evolving landscape of database technologies, the introduction of TreeLine marks a significant milestone. Designed explicitly for the advanced capabilities of Non-Volatile Memory Express (NVMe) solid-state drives, TreeLine ingeniously melds the reliability and structural advantages of traditional B+ trees with cutting-edge enhancements suited for modern storage environments. This novel approach not only caters to the high-performance demands of contemporary applications but also intelligently addresses some of the longstanding inefficiencies in previous database architectures.
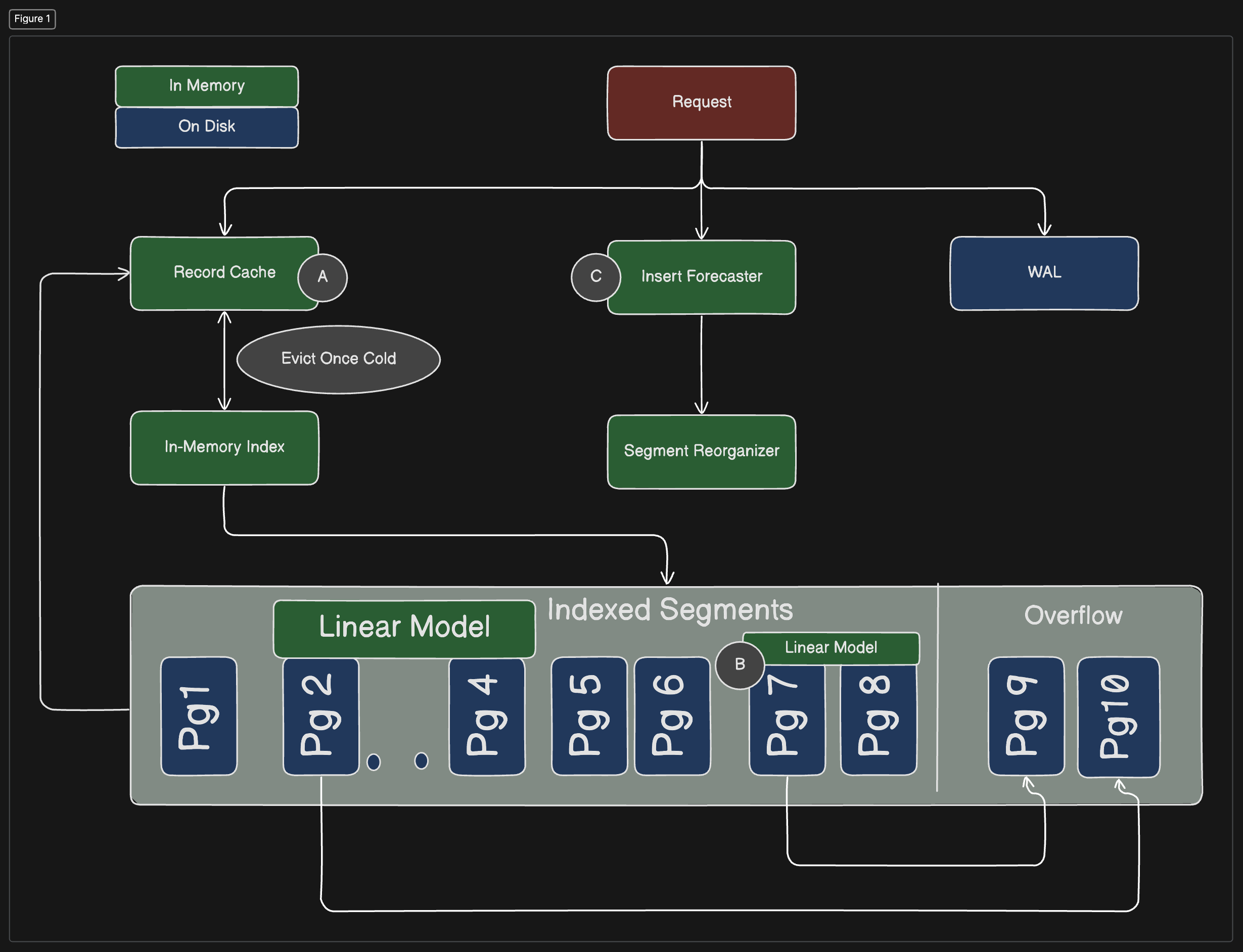
Innovative Techniques in TreeLine
(A) Record Caching
- The primary goal of record caching in TreeLine is to minimize the amplification of reads and writes, a common problem in traditional database systems where updating or reading a small piece of data requires loading and possibly writing an entire disk page.
- TreeLine maintains a cache of records, likely in memory, which allows frequently accessed ("hot") data to be accessed quickly without the need to repeatedly read from and write to the disk. This is particularly useful in workloads where certain data items are accessed more frequently than others, a scenario known as a "skewed" workload.
- By keeping hot records in memory and batching updates to the same on-disk page, TreeLine reduces the I/O required for updating pages, thereby lowering read/write amplification and improving overall performance.
(B) Page Grouping
- Page grouping aims to optimize the physical layout of data on disk to improve the performance of scan operations and reduce the overhead caused by random reads.
- In TreeLine, pages that store adjacent key ranges are organized to be stored contiguously on the disk. This means that keys that are logically adjacent are also physically adjacent, facilitating faster access during range scans.
- When data is stored contiguously, scanning through a range of keys becomes much faster because the system can perform efficient long sequential reads instead of slower random reads. This arrangement also benefits point reads (accessing a single record) because the system can predictably locate data with fewer disk seeks.
(C) Insert Forecasting
- This technique is used to manage how space is allocated on disk pages more efficiently, addressing a common inefficiency in update-in-place models where inserting new records can lead to significant restructuring of the on-disk data.
- TreeLine uses patterns in past insert operations to predict future inserts, both in terms of the location (which pages) and the volume (how many records).
- By anticipating where and how many new records will be inserted, TreeLine can proactively allocate space on the appropriate pages. This foresight reduces the need for frequent and costly page reorganizations, which would otherwise be necessary to make room for new data. The system, therefore, maintains high performance and stability even as the dataset grows and changes.
Conclusion
Throughout this discussion, we have explored the evolving landscape of database performance, underscored by the transition from traditional storage solutions like HDDs and early SSDs to cutting-edge NVMe SSDs. The shift from log-structured merge-tree (LSM) systems, which once dominated the field with their sequential write advantages, to architectures that fully exploit the speed and efficiency of NVMe technology marks a significant milestone in database design.
TreeLine emerges as a standout innovation in this context, merging the reliability and efficiency of B+ trees with new techniques such as record caching, page grouping, and insert forecasting. These advancements are not just technical improvements but are pivotal in reducing operational overhead and enhancing performance. The compelling results from performance evaluations, which show TreeLine's superiority over traditional LSM-based systems and update-in-place models, pave the way for rethinking database architecture in light of modern storage capabilities.
As database administrators and system architects, the insights gained here should prompt a reevaluation of existing data management strategies, encouraging a shift toward more dynamic and efficient systems aligned with technological progress. The potential for NVMe SSDs to revolutionize database performance is vast, and the introduction of TreeLine is just a glimpse of the future possibilities.
Refereces
This blog is inspired by TreeLine research paper